BDB-Lab members involved

SemiBin2: self-supervised contrastive learning leads to better MAGs for short- and long-read sequencing
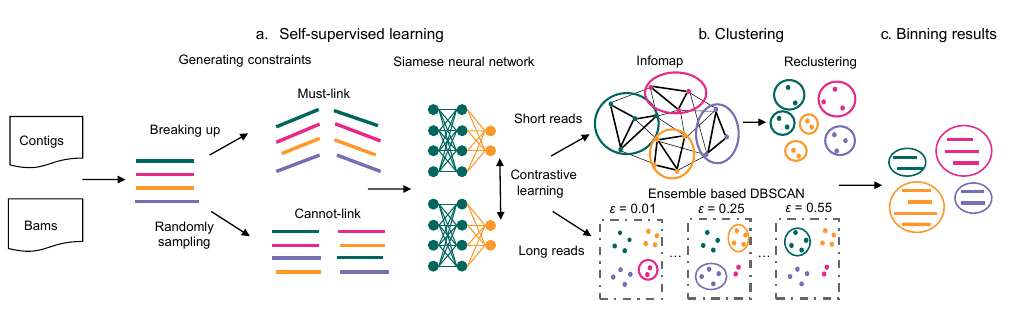
SemiBin2: self-supervised contrastive learning leads to better MAGs for short- and long-read sequencing
by Shaojun Pan, Xing-Ming Zhao, Luis Pedro Coelho
Abstract
Motivation: Metagenomic binning methods to reconstruct metagenome-assembled genomes (MAGs) from environmental samples have been widely used in large-scale metagenomic studies. The recently proposed semi-supervised binning method, SemiBin, achieved state-of-the-art binning results in several environments. However, this required annotating contigs, a computationally costly and potentially biased process.
Results: We propose SemiBin2, which uses self-supervised learning to learn feature embeddings from the contigs. In simulated and real datasets, we show that self-supervised learning achieves better results than the semi-supervised learning used in SemiBin1 and that SemiBin2 outperforms other state-of-the-art binners. Compared to SemiBin1, SemiBin2 can reconstruct 8.3%–21.5% more high-quality bins and requires only 25% of the running time and 11% of peak memory usage in real short-read sequencing samples. To extend SemiBin2 to long-read data, we also propose ensemble-based DBSCAN clustering algorithm, resulting in 13.1%–26.3% more high-quality genomes than the second best binner for long-read data.
Availability and Implementation: SemiBin2 is available as open source software at https://github.com/BigDataBiology/SemiBin/ and the analysis scripts used in the study can be found at https://github.com/BigDataBiology/SemiBin2_benchmark.
Copyright (c) 2018–2024. Luis Pedro Coelho and other group members. All rights reserved.